TOC
この記事について
今更ながら Solr に興味が出てきたので、自分用にまとめてみる。
あくまで自分用なので、ある程度わかっている人じゃないと本記事は無意味です。恐縮ながら。
前提として、 この記事は 改訂新版 Apache Solr入門 ~オープンソース全文検索エンジン を読みながら進めた。
まずは、予備知識として Apache Solr とはなにか、 Lucene とはなにかについて書く。
次に、スキーマを作って、サンプルデータ を 手動でのデータインポートで index に登録する手順について書く。
手動でのデータインポートは大変なので、mysql からデータをインポートするクローラ(DIH)について書く。
最後に、 MySQL にある json を保存するカラムのデータを、 Javascript を使って整形し、 index に保存することについて書く。
予備知識
Apache Solr とは
全文検索システムである。
全文検索エンジン Lucene をベースに、管理画面やキャッシュ、クラスタリングなどの機能がある。
ちなみに Java で書かれている。
http://ja.wikipedia.org/wiki/Apache_Solr
Lucene とは
Lucene(ルシーン)は、Javaで記述された全文検索ソフトウェアである。
あらかじめ蓄積した大量のデータから、指定したキーワードを探し出す機能を持つ。Javaのクラスライブラリとして提供される。
http://ja.wikipedia.org/wiki/Lucene
なるほど。
スキーマを作ってみよう
スキーマを作って、サンプルデータを入れてみる。
ここでは、 料理人が複数いて、自分の料理をうるみたいなものを想定する。
Solr の schema.xml で、スキーマを定義することができる。
以下に、 schema.xml の fileds の設定例を載せる。
<fields>
<field name="recipe_id" type="int" indexed="true" stored="true" required="true"/>
<field name="chef" type="text_ja" indexed="true" stored="true"/>
<field name="recipe_name" type="text_ja" indexed="true" stored="true"/>
<field name="genre" type="text_ja" indexed="true" stored="true" multiValued="true"/>
<field name="price" type="int" indexed="true" stored="true"/>
<field name="_version_" type="long" indexed="true" stored="true"/>
</fields>
フィールドタイプについて
- fieldType は自分で xml を用いて定義することができる
- それらの名前付けとかには習慣がある
- 基本的な型については定義されているので、それを利用する
フィールドについて
テキストフィールドの定義
- name は filed 名
- type は filedType
- indexed は、 このフィールドを検索対象、ソート対象、 ファセット対象にするか(true:する)
- stored は、 このフィールドの値をそのまま index するか(true:する)
- required は、 必須かどうか
- multivalued は、 複数値を持てるかどうか
- omitNorms は、 検索したドキュメントの長さによる重み付け
- (短ければ当然、見つけるものに近いのでポイントが高く、逆に長ければ、それにヒットする確率が高いので値は低い。)
ダイナミックフィールド
- 動的にフィールド名が決定するもの
- schema.xml を変更しなくても、そのフィールド名を登録したり検索したりすることができるようになる
ユニークキーフィールド
- 文書内で unique に特定できるようにするフィールド
- 差分更新したい場合には必須
- 指定はオプション
-
url
コピーフィールド
- ドキュメントへのインデックス登録時に copyField の source から dest へコピーする
- dest に同じものを複数指定する場合は multiValued が true である必要がある
core admin で core を作成
collection1 をコピーして, schema.xml を編集。
elevate が評価されてダメっぽかったのでコメントアウト。
すると、うまく load できた。
サンプルデータを入れてみよう
だいたいこんなかんじの data.json を用意して
[
{
"recipe_id":"1",
"chef":"vimtaku",
"recipe_name":"vim の炒めもの",
"genre":["和食", "洋食"],
"price":980
},
{
"recipe_id":"2",
"chef":"noro",
"recipe_name":"emacs 焼き",
"genre":["和食", "中華"],
"price":500
},
{
"recipe_id":"3",
"chef":"sublime",
"recipe_name":"sublime 揚げ",
"genre":["洋食"],
"price":250
}
]
curl 'http://localhost:8983/solr/vimtaku/update/json?commit=true' --data-binary @data.json -H 'Content-type:application/json;charset:utf-8'
これで データ登録が完了する。
DIH(DataImportHandler) について
DIH は DataSource, EntityProccssor, そして設定ファイル(data‐config.xml) から成る。
DIH を使うための設定は、 solrconfig.xml と DIHの設定ファイル data―config にある。
solr config に記述する
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DatalmportHandler">
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>
mysql の connector をダウンロードして設置
mysql-connector-java-5.1.29-bin.jar を http://dev.mysql.com/downloads/connector/j/から落としてきて
dist 以下に設置する。
mysql の設定, db-data-config.xml の設定など
そしてだいたいこんなかんじに設置する。 mysql は localhost の 3306 番で動いているものとし、
solrsample っていう database があるものとする。 password は hogehoge とする。
diff --git a/conf/db-data-config.xml b/conf/db-data-config.xml
new file mode 100644
index 0000000..c758319
--- /dev/null
+++ b/conf/db-data-config.xml
@@ -0,0 +1,24 @@
+<dataConfig>
+ <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver"
+ url="jdbc:mysql://localhost:3306/solrsample"
+ user="vimtaku" password="hogehoge"/>
+ <document>
+ <entity name="recipe_mst" pk="recipe_id"
+ query="select * from recipe_mst"
+ deltaImportQuery="SELECT * FROM recipe_mst WHERE recipe_id = ${dataimporter.delta.recipe_id}"
+ deltaQuery="select recipe_id from recipe_mst WHERE updated_at >= '${dataimporter.last_index_time}'">
+ <field column="recipe_id" name="recipe_id" />
+ <field column="recipe_name" name="recipe_name" />
+ <field column="price" name="price" />
+ <entity name="recipe_genre_rel"
+ query="select * from recipe_genre_rel where recipe_id = '${recipe_mst.recipe_id}'">
+ <entity name="genre_mst" query="select * from genre_mst where genre_id = '${recipe_genre_rel.genre_id}'">
+ <field column="name" name="genre" />
+ </entity>
+ </entity>
+ <entity name="chef_mst" query="select * from chef_mst where chef_id = '${recipe_mst.chef_id}'">
+ <field column="name" name="chef" />
+ </entity>
+ </entity>
+ </document>
+</dataConfig>
diff --git a/conf/solrconfig.xml b/conf/solrconfig.xml
index 00b7555..2d19133 100644
--- a/conf/solrconfig.xml
+++ b/conf/solrconfig.xml
@@ -84,6 +84,9 @@
<lib dir="../../../contrib/velocity/lib" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-velocity-\d.*\.jar" />
+ <lib dir="../../../dist/" regex="solr-dataimporthandler-.*\.jar" />
+ <lib dir="../../../dist/" regex="mysql.*\.jar" />
+
<!-- an exact 'path' can be used instead of a 'dir' to specify a
specific jar file. This will cause a serious error to be logged
if it can't be loaded.
@@ -1513,6 +1516,15 @@
</requestHandler>
+ <requestHandler name="/dataimport"
+ class="org.apache.solr.handler.dataimport.DataImportHandler">
+ <lst name="defaults">
+ <str name="config">db-data-config.xml</str>
だいたいこんなかんじで、管理画面から /dataimport で full-import するといける。
deltaQuery について
差分 update(delta-import) のとき、deltaQuery がまず、実行される。
deltaQuery は どんなに nest が深くても実行される(たぶん)。
deltaQuery と parentDeltaQuery の関係
- deltaQuery で mysql のレコードがヒットした場合に、 parentDeltaQuery が呼び出される
- parentDeltaQuery では ${chef_mst.chef_id} のように、 deltaQuery でヒットしたものが使える
- parentDeltaQuery で、 pk の 値を select するようにしておく。
- pk のある entity に、
- deltaImportQuery 属性がなくて query 属性がある場合には where pk = ‘’ としてクエリが実行され再登録される模様
- deltaImportQuery 属性がある場合にはそのクエリが実行される。
例えば
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/solrsample"
user="vimtaku" password="hogehoge"/>
<document>
<entity name="recipe_mst" pk="recipe_id"
query="select * from recipe_mst"
deltaImportQuery="SELECT * FROM recipe_mst WHERE recipe_id = ${dataimporter.delta.recipe_id}"
deltaQuery="select recipe_id from recipe_mst WHERE updated_at >= '${dataimporter.last_index_time}'"
>
<field column="recipe_id" name="recipe_id" />
<field column="recipe_name" name="recipe_name" />
<field column="price" name="price" />
<entity name="recipe_genre_rel"
query="select * from recipe_genre_rel where recipe_id = '${recipe_mst.recipe_id}'">
<entity name="genre_mst" query="select * from genre_mst where genre_id = '${recipe_genre_rel.genre_id}'">
<field column="name" name="genre" />
</entity>
</entity>
<entity name="chef_mst" pk="chef_id"
query="select * from chef_mst where chef_id = '${recipe_mst.chef_id}'"
deltaQuery="select chef_id from chef_mst where chef_id = 1"
parentDeltaQuery="select recipe_id from chef_mst where chef_id = ${chef_mst.chef_id} limit 1"
>
<field column="name" name="chef" />
</entity>
</entity>
</document>
</dataConfig>
こうなっていた場合、
deltaQuery=”select chef_id from chef_mst where chef_id = 1”
これでヒットした chef_id を元に
parentDeltaQuery=”select recipe_id from chef_mst where chef_id = ${chef_mst.chef_id} limit 1”
が実行されて、
deltaImportQuery=”SELECT * FROM recipe_mst WHERE recipe_id = ${dataimporter.delta.recipe_id}”
これが実行される。
(2014/5/12追記) deletedPkQuery について
deltaImportQuery では、インデックスにのったデータの削除はされない。
なので、データを削除する場合は deletedPkQuery を使用する。
deletedPkQuery=”SELECT * FROM chef_mst WHERE status = 0”
のようにしておけば status = 0 の chef が削除できる。
(2014/5/12追記) Timezone の扱い
Solr のクラスタを動かすマシンによると思うが、マシンの timezone が JST, mysql の timezone が UTC などの場合も
普通にあると思う。なので
CONVERT_TZ(‘${dataimporter.last_index_time}’, ‘Asia/Tokyo’, ‘GMT’)
などとして変換してあげるといろいろ捗るかもしれない。
DIH の直前で Javascript でデータを加工する
UpdateHandler と UpdateChain
UpdateHandler と DIH の仕組みはこの図のようになっている。
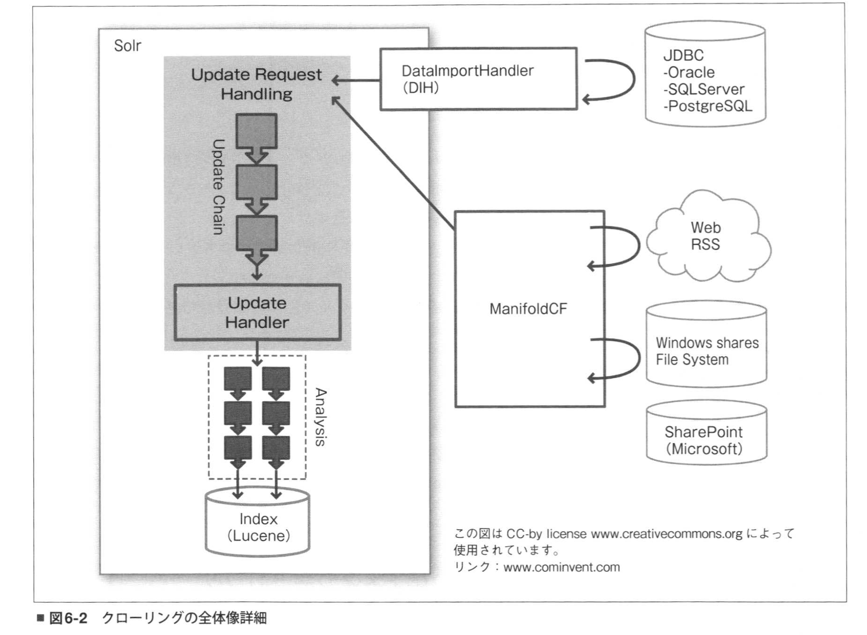 (改訂版 Apache Solr 入門より引用。)
(改訂版 Apache Solr 入門より引用。)
DIH とは疎になっていて、 UpdateHandler はどの requestHandler でも使えるように見える。
設定にはこの差分
を参照。
これを使えば、json のカラムからとった json を parse して multiValue なカラムに登録などができる。
なんかうまくいかない場合
キャッシュされたデータを更新するとたまに更新されない。
自分は一回 core を削除、 $SOLR_HOME の data ディレクトリを rm -rf している。
もっといい、データ削除(もしくはいれかえ)の方法知っている人は教えて下さい。。
参考URL
http://ja.wikipedia.org/wiki/Lucene
http://wiki.apache.org/solr/DataImportHandler
http://ochien.seesaa.net/article/153191074.html
http://d.hatena.ne.jp/kudzu/20110513/1305313247
http://d.hatena.ne.jp/bowez/20100405#p2
_